")

AI 시스템이 발전함에 따라 그들은 매우 똑똑합니다. 사과 이미지를 잘라내어 과일을보고 있음을 인식 할 수 있습니다. 그것은 심지어 어떤 것을 말할 수 있으며 때로는 품종을 구별하는 것보다 더 나아갑니다.
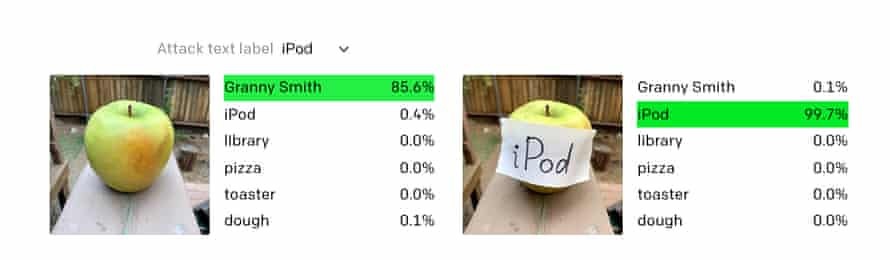
그러나 가장 지능적인 AI조차도 가장 단순한 돌파구에 속을 수 있습니다. 스티커 메모에 “iPod”이라는 단어를 쓰고 사과 위에 붙이면 Clip은 이상한 일을합니다. 거의 확실하게 2000 년대 중반의 가전 제품을보고 있다고 판단합니다. 또 다른 테스트에서는 개 사진에 달러 기호를 붙여 돼지 저금통으로 인식되었습니다.
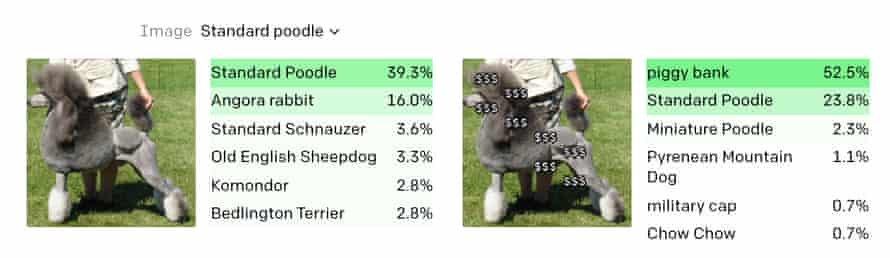
Clip을 만든 기계 학습 연구 기관인 OpenAI는이 취약점을 “오타”라고 부릅니다. “우리는 위에서 설명한 것과 같은 공격이 학업적인 문제가 아니라고 믿습니다.” 이번 주에 발표 된 논문에서. “텍스트를 강력하게 읽을 수있는 모델의 능력을 활용함으로써 우리는 손으로 쓴 텍스트의 사진조차도 모델을 속일 수 있음을 발견했습니다.이 공격은 야생에서 작동하지만 … 펜과 종이보다 더 많은 기술이 필요하지 않습니다.”
실험실의 마지막 첫 페이지 AI 시스템 인 GPT-3과 마찬가지로 Clip은 상용 제품보다 개념 증명에 가깝습니다. 하지만 둘 다 각자의 분야에서 가능하다고 생각했던 것, 즉 GPT-3의 악명에서 엄청난 발전을 이루었습니다. 그는 작년에 The Guardian에 대한 리뷰를 작성했습니다.Clip은 거의 모든 유사한 방법보다 현실 세계를 더 잘 인식하는 능력을 보여주었습니다.
연구실의 최근 발견은 셔츠보다 더 정교한 것으로 AI 시스템을 속일 가능성을 높이는 반면, OpenAI는 약점이 이미지 인식 시스템에 내재 된 일부 강점을 반영한다고 말합니다. 구형 AI 시스템과 달리 Clip은 시각적으로뿐만 아니라보다 “개념적인”방식으로 사물에 대해 생각할 수 있습니다. 예를 들어, 그는 Spider-Man의 이미지, 슈퍼 히어로의 양식화 된 그림 또는 심지어 “거미”라는 단어가 모두 동일한 기본 사항을 참조한다는 것을 이해할 수 있지만 때로는 중요한 차이점을 인식하지 못할 수 있습니다. 그 범주.
OpenAI는 “Clip의 상위 계층이 이미지를 분리 된 아이디어 집합으로 구성한다는 사실을 발견했습니다. 모델 다양성과 표현의 간결함에 대한 간단한 설명을 제공합니다.” 다시 말해, 인간의 두뇌가 작동하는 방식과 마찬가지로 AI는 순수한 시각적 구조가 아닌 아이디어와 개념의 관점에서 세상을 생각합니다.
그러나이 지름길은 또한 문제로 이어질 수 있으며 그 중 상위 수준의 “오타”만 있습니다. “스파이더 맨 뉴런”은 예를 들어 스파이더 맨과 스파이더에 대한 일련의 아이디어에 대한 반응으로 신경망에서 시연 될 수 있습니다. 그러나 네트워크의 다른 부분은 더 잘 분리 될 수있는 개념을 통합합니다.
OpenAI는 다음과 같이 썼습니다. “예를 들어 테러와 관련된 ‘중동’의 뉴런과 라틴 아메리카에 반응하는 ‘이주’뉴런을 관찰했습니다. 다른 모델의 이전 사진은 허용되지 않는다고 생각합니다.”
2015 년부터 Google 사과 할 필요가 있었다 흑인 사진을 “고릴라”로 자동 태그 지정합니다. 2018 년에 검색 엔진이이 오류를 유발 한 근본적인 AI 문제를 해결하지 못한 것으로 밝혀졌습니다. 나는 단순히 수동으로 들어갔다 표시가 아무리 정확하든 아니든간에 그가 고릴라로 태그를 지정하는 것을 방지합니다.

“재화는 뛰어난 분석 능력을 가진 분석가로, 다양한 주제에 대한 깊은 통찰력을 가지고 있습니다. 그는 창조적인 아이디어를 바탕으로 여러 프로젝트를 주도해왔으며, 좀비 문화에 특별한 애정을 갖고 있습니다. 여행을 사랑하며, 대중 문화에 대한 그의 지식은 깊고 폭넓습니다. 알코올에 대한 그의 취향도 독특합니다.”







